
In different Machine learning and Data analytics models, we have to deal with large datasets with an ‘N’ number of columns and rows. Sometimes, we need to find the difference between the data values of the rows. In this article, we will see some queries to find the difference between the rows. Let’s start with the importance of finding the difference.
Importance of Calculating the Difference
- Data Validation: Calculating the difference between two rows is really important to validate the data, accuracy, and prevent errors.
- Detecting Changes: Looking at the adjacent columns will help discover whether the changes that took place in the data represent users’ activity, preferences or any market shift.
- Calculating Rates of Change: The difference between two data points can be measured by a specific time period using SQL, which can then be used to calculate rates of change, growth rates, or even percentages in data analysis models.
- Data Cleansing: Identifying the difference between data points helps to detect errors and leads to data cleansing. The process of data analysis becomes easy due to the clean database.
Methods To Calculate the Difference Between Two Rows
The difference between two rows can be calculated by comparing two columns. First, we will try to compare two columns from the table, then we can also try to compare all the columns from the table. Another technique to compare different rows is to spot the different rows from the table.
1. By Comparing Two Columns
The simple way to get the difference between two rows is to compare the elements from the columns.
Take an example of a table ‘table_1’ to implement the trick. This trick works based on the logic that a SELECT statement with a WHERE clause applies to the condition.
Sample table_1:
CREATE TABLE table_1 (
OrderID_info INT,
CustomerID_info INT,
ProductName_info VARCHAR(50),
OrderDate_info DATE,
OrderAmount_info DECIMAL(10, 2),
profit_info INT
);
INSERT INTO table_1 VALUES (1, 11, 'A', '2024-01-01', 1000.00, 500);
INSERT INTO table_1 VALUES (2, 12, 'B', '2024-01-02', 3000.00, 100);
INSERT INTO table_1 VALUES (3, 13, 'C', '2024-01-03', 50.00, 50);
INSERT INTO table_1 VALUES (4, 14, 'D', '2024-01-04', 500.00, 50);
INSERT INTO table_1 VALUES (5, 15, 'E', '2024-01-05', 800.00, 400);Code language: SQL (Structured Query Language) (sql)Query:
SELECT *
FROM table_1
WHERE OrderAmount_info <> profit_info ;
Code language: SQL (Structured Query Language) (sql)In this case, we compare the profit and order amount. If the order profit and order amount are the same then exclude the output. Now let us look for the output for validation.
Output:
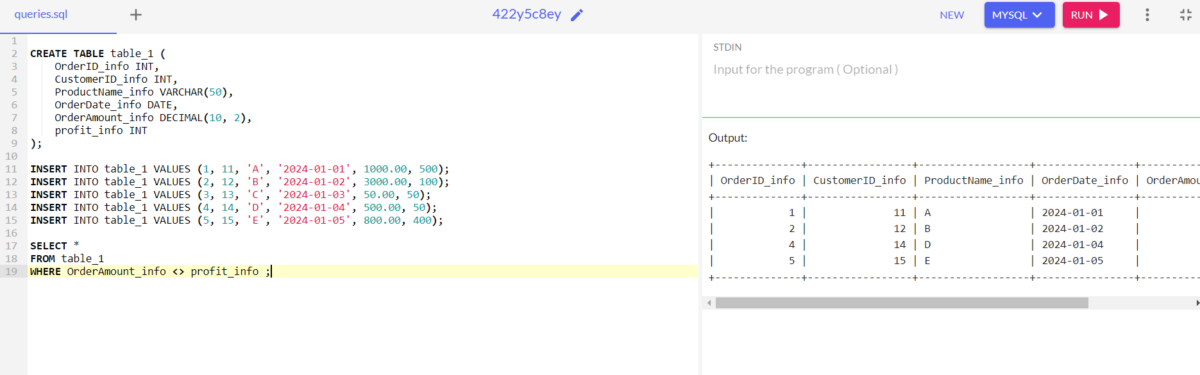
In the outcome, we can see that product C is excluded from the list of rows.
2. By Comparing All Columns
Let’s try to compare every column in this example, to be able to distinguish the two rows in the table. Moreover, we can organize the data coming from the table by using the logic of the WHERE and AND to distinguish the rows from the table. Let’s look at the query.
Sample table_2:
CREATE TABLE table_2 (
EmployeeID_info INT,
FirstName_info VARCHAR(50),
LastName_info VARCHAR(50),
Salary_info DECIMAL(10, 2)
);
INSERT INTO table_2 VALUES (1, 'A', 'X', 150000.00);
INSERT INTO table_2 VALUES (2, 'B', 'Y', 200000.00);Code language: SQL (Structured Query Language) (sql)Query:
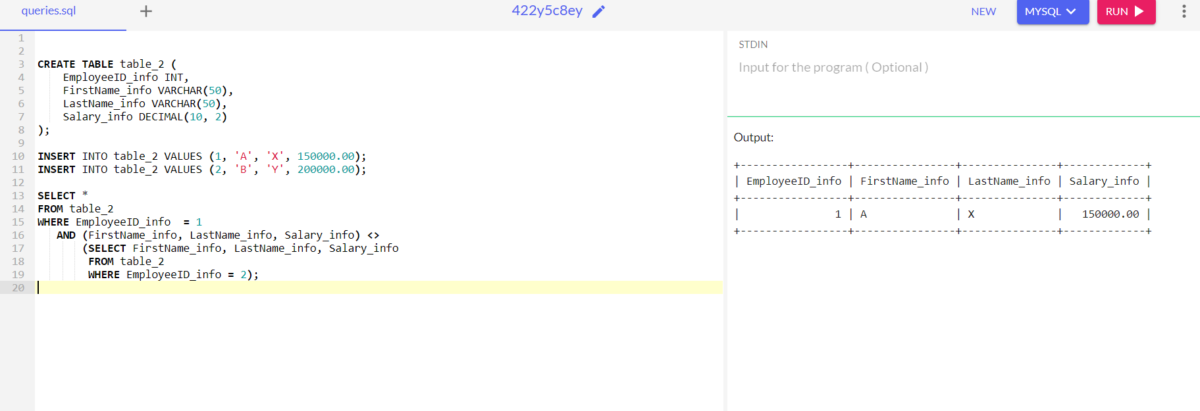
SELECT *
FROM table_2
WHERE EmployeeID_info = 1
AND (FirstName_info, LastName_info, Salary_info) <>
(SELECT FirstName_info, LastName_info, Salary_info
FROM table_2
WHERE EmployeeID_info = 2);
Code language: SQL (Structured Query Language) (sql)Output:
3. By Using the EXCEPT Operator
Another method to differentiate two rows using columns is to use the EXCEPT operator. The EXCEPT operator is used to sort the data present in the two tables or the two rows. The EXCEPT operator is not supported by all the databases. If your database supports the EXCEPT operator then, you can try this and use this method to differentiate two rows in SQL.
Sample table_3:
CREATE TABLE sample_table (
region VARCHAR(50),
country VARCHAR(50),
amount NUMERIC
);
INSERT INTO sample_table (region, country, amount) VALUES
('Asia', 'Japan', 1000),
('Asia', 'China', 1500),
('Asia', 'India', 1200),
('Europe', 'France', 2000),
('Europe', 'Germany', 2500),
('North America', 'USA', 3000),
('North America', 'Canada', 1800);Code language: SQL (Structured Query Language) (sql)Query:
SELECT region, country, amount
FROM sample_table
WHERE country = 'USA'
EXCEPT
SELECT region, country, amount
FROM sample_table
WHERE country = 'Canada';Code language: SQL (Structured Query Language) (sql)Output:
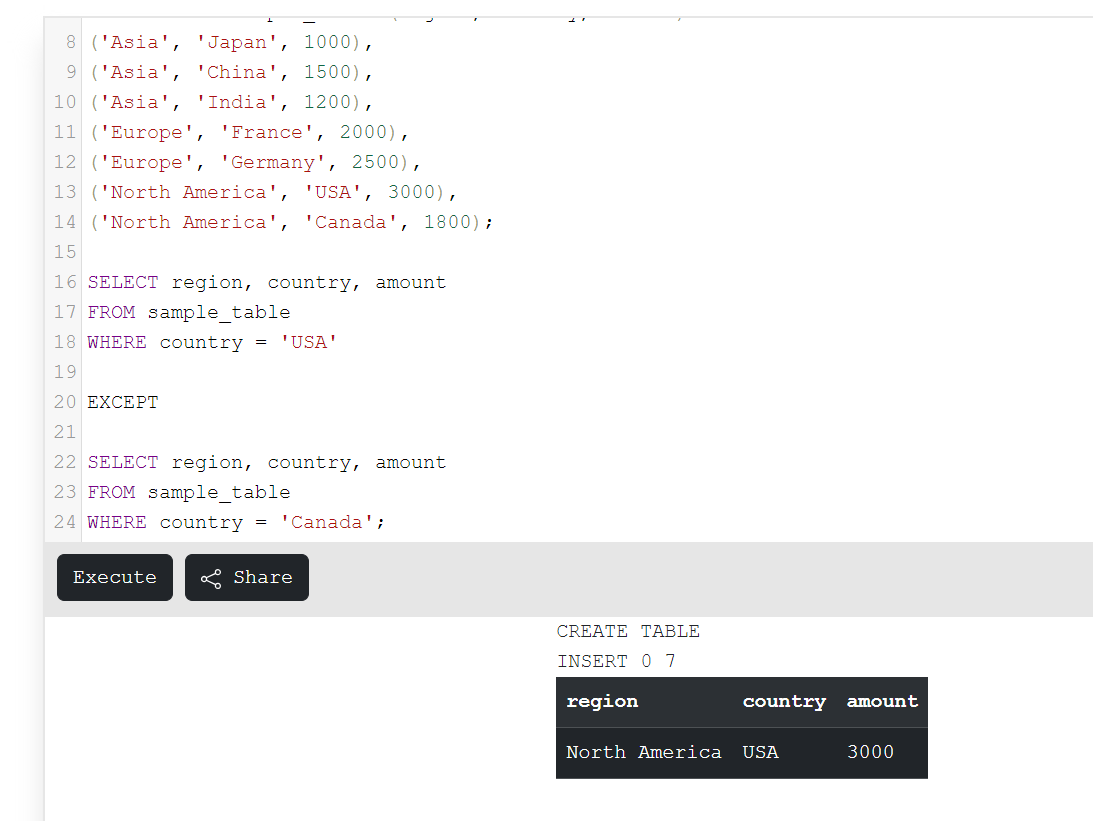
All three methods are effective and accurate. You can use any method to differentiate the two rows in SQL. Try this technique on your database and get results.
Summary
In this article, three different techniques to differentiate two rows in SQL are explained with the help of examples and sample tables. The advantage of differentiating two rows is also explained in detail. Techniques 1 and 2 are used with any database, but technique 3 employs the EXCEPT operator, which is not supported by all the databases. These techniques are simple and easy to use. Hope you will understand the concept and enjoy the article.
Reference
https://stackoverflow.com/questions/634568/how-to-get-difference-between-two-rows-for-a-column-field