
Indexes play a vital role when it comes to the SQL server. While writing SQL queries if you want to increase the performance and data retrieval timing, an index can play a crucial role in that. To understand better, let’s take a dictionary as an example, it has an index and with the help of that, the process of searching for any word is usually easy. In this tutorial, we will learn about clustered and non-clustered indexes, with the help of practical examples.
Clustered Index
Imagine a scenario where you are organizing your clothes in a wardrobe based on color. You can only organize them by one color at a time. So, if you have a wardrobe sorted by color, finding a specific color shirt is easy because they’re all grouped together.
After organizing the table data into physical order, SQL Server constructs a set of index pages that enable queries to navigate directly to the data they seek. In SQL, a clustered index table refers to the physical order of records. Since there can only be one clustered index per table, it is important to choose wisely based on access patterns and query requirements.
Also Read: MySQL Index Hints – FORCE INDEX
How to Create a Clustered Index
A clustered index can automatically be created when we apply a primary key to any column.
Now, let’s follow the below steps, to create a table named Employee data with a primary key on the ID column using the below query:
CREATE TABLE EmployeeRecord (
ID INT PRIMARY KEY,
Name VARCHAR(255),
Department VARCHAR(255),
Salary DECIMAL(10, 2)
);
INSERT INTO EmployeeRecord (ID, Name, Department, Salary) VALUES
(2, 'Akash Sharma', 'IT', 50000.00),
(1, 'Aarti Singh', 'HR', 45000.00),
(3, 'Rahul Gupta', 'Finance', 55000.00),
(5, 'Neha Patel', 'Marketing', 48000.00),
(4, 'Priya Sharma', 'IT', 52000.00);Code language: SQL (Structured Query Language) (sql)As we can see the primary key is set to the ID column, and it will automatically start behaving as a clustered index. To see the output:
SELECT * FROM EmployeeData;Code language: SQL (Structured Query Language) (sql)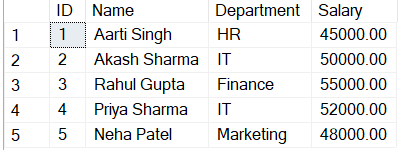
From the above, we can see that the table is in increasing order of ID even when we have inserted the data where IDs were shuffled.
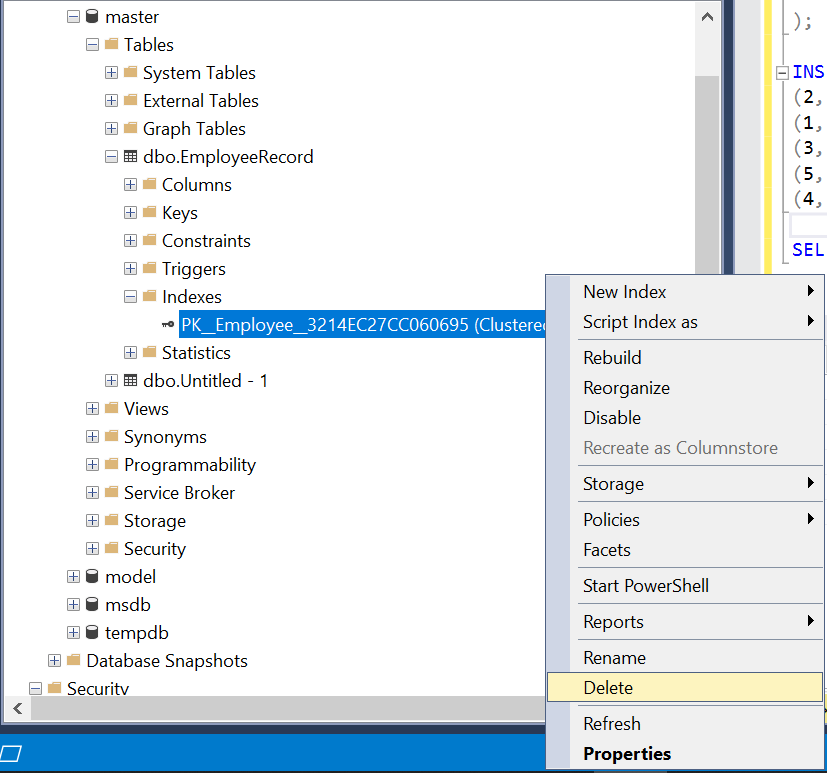
While a table can only have one clustered index, a clustered index can be composite, which means it can be composed of multiple columns. So to create a custom, we are going to use the same table but before doing that first we need to delete the cluster index which is created previously. So to delete it:
- Select the table.
- Select the Indexes folder of that table.
- Select Primary Index, then Right Click on it and click on Delete.
Now use the below query to create a clustered index:
CREATE CLUSTERED INDEX index_name
ON table_name (column_name [ASC | DESC], ...);Code language: SQL (Structured Query Language) (sql)Let’s create a clustered index where Name will be in ascending order:
CREATE CLUSTERED INDEX IX_tblEmployeeRecord_Name
ON EmployeeRecord(Name ASC)Code language: SQL (Structured Query Language) (sql)To see the output:
SELECT * FROM EmployeeRecord;Code language: SQL (Structured Query Language) (sql)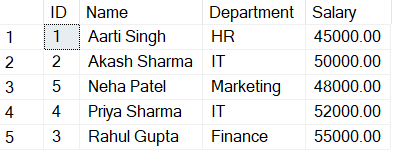
Also Read: MySQL IS NULL Optimization in Index
Non-Clustered Index
Consider that you currently own a list of your top films, and you have arranged them in a different list, alphabetically listing each movie with its corresponding category, rather than by genre. The Non-clustered index looks like this particular list. With your movies organized, you can easily find a specific movie without actually changing the order of your movies.
Non-clustered indexes are kept separate from the actual data. The table can have multiple non-clustered indexes, providing different ways to access the data depending on the indexed columns
How to Create a Non-Clustered Index
To create a non-clustered index, use the below query:
CREATE NONCLUSTERED INDEX index_name
ON table_name (column_name [ASC | DESC], ...);Code language: SQL (Structured Query Language) (sql)Now, let’s create a non-clustered index on the name column:
CREATE NONCLUSTERED INDEX IX_tblEmployeeRecord_Name
ON EmployeeRecord(Name ASC);Code language: SQL (Structured Query Language) (sql)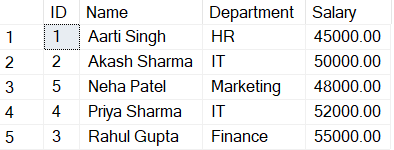
The index on the Name column would change from being a clustered index to a non-clustered index. The change in the indexing scheme won’t affect the table’s structure, it only affects the performance and behaviour of queries that utilize the indexes.
Clustered vs Non-Clustered Index
| Feature | Clustered Index | Non-Clustered Index |
| Physical Data Storage | Data rows are stored in the order of the index key. | Data rows and index entries are stored separately. |
| Number per Table | Only one per table. | Multiple per table. |
| Retrieval Efficiency | Efficient for range queries and sequential access. | Efficient for individual row lookups and joins. |
| Impact on Data Updates | Updates may cause page splits and fragmentation. | Data updates typically have less impact. |
| Sorting | Defines the physical order of the data. | Does not affect the physical order of the data. |
Conclusion
Clustered Index physically order data in a table which benefits the range queries, but it potentially slows down the data updates whereas Non-clustered indexes store index entries separately, and optimize individual row lookups without affecting data order. Both are important tools for optimizing the performance of the database. In this tutorial, we have learned how to use them with the help of practical examples. We hope you enjoyed it.
Reference
https://stackoverflow.com/questions/1251636/what-do-clustered-and-non-clustered-index-actually-mean