
PostgreSQL is the open-source with the free functionality that you can use to perform certain tasks. The ability of the PostgreSQL language is upgraded with various extensions that will be applicable for different kinds of models for operation complexity. Here, we are going to analyze the aggregate function PostgreSQL GROUP BY extension deeply. The GROUP BY clause refers to the core attribute of joining by stating the columns and their data, which are to be grouped from large and complex databases. The article will give you an outlook of what the Group By extensions are, who they apply to, and what their role is.
ROLLUP
The roll-up extension in PostgreSQL boosts the capabilities of the standard SQL GROUP BY operator by allowing for the creation of group subtotals and grand totals for grouped data. This extension allows for hierarchical aggregation which involves augmenting the result set with extra rows that represent various hierarchical levels of aggregation. This feature is especially helpful in reporting and analytics cases, where users can analyze data on different levels of granularity without the need for separate queries.
Let’s see an example based on rollup extension.
CREATE TABLE sampletable1 (
region_1 VARCHAR(50),
product_2 VARCHAR(50),
year INT,
revenue_4 NUMERIC
);
-- Inserting sample data into the sales_data table
INSERT INTO sampletable1 (region_1, product_2, year, revenue_4) VALUES
('North', 'Product A', 2021, 10000),
('North', 'Product A', 2022, 12000),
('North', 'Product B', 2021, 15000),
('North', 'Product B', 2022, 18000),
('South', 'Product A', 2021, 9000),
('South', 'Product A', 2022, 11000),
('South', 'Product B', 2021, 13000),
('South', 'Product B', 2022, 16000);
Code language: SQL (Structured Query Language) (sql)SELECT region_1, product_2, year, SUM(revenue_4) AS total_revenue
FROM sampletable1
GROUP BY ROLLUP(region_1, product_2, year);
Code language: SQL (Structured Query Language) (sql)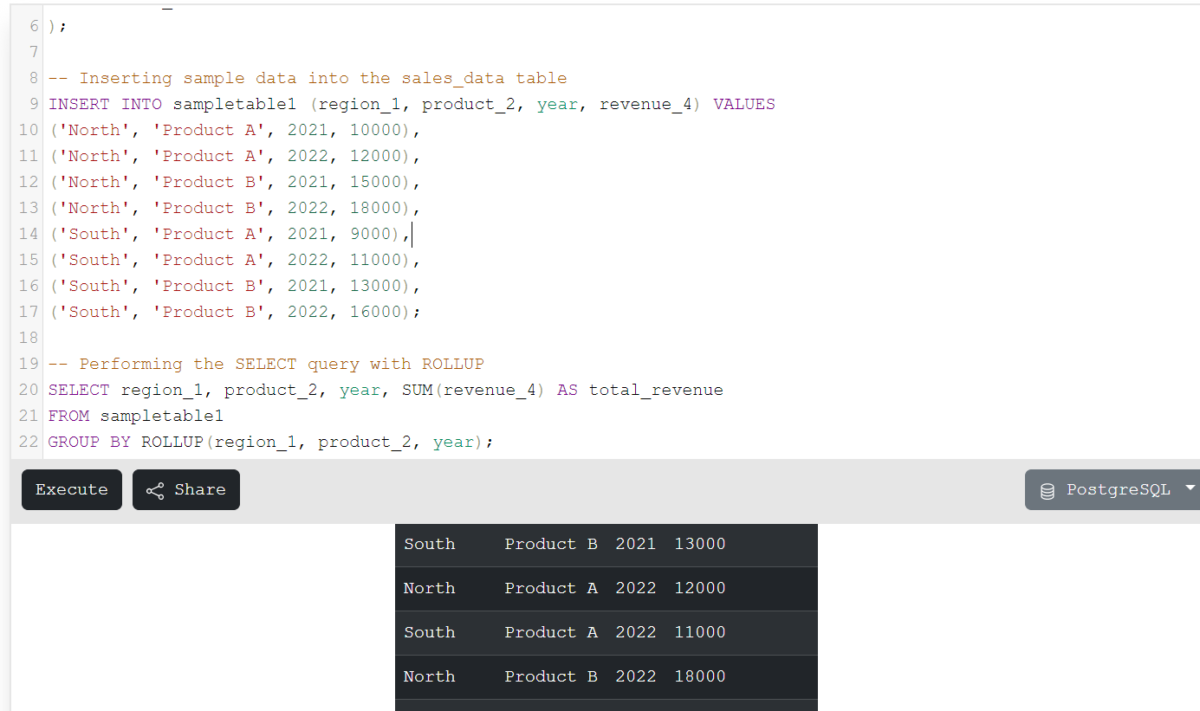
CUBE
The cube extension in PostgreSQL extends the features of the GROUP BY operator through multidimensional grouping and aggregation. Cube lets you build roll-ups for any possible combinations of columns that are specified, which thereby allows a more complete analysis of data across multiple dimensions. It is particularly handy while working with data sets that have multiple attributes or dimensions, and the analysis demands looking through various combinations of them in parallel. To understand the concept in detail let’s see an illustration.
SELECT region_1, product_2, year, SUM(revenue_4) AS total_revenue
FROM sampletable1
GROUP BY CUBE(region_1, product_2, year);
Code language: SQL (Structured Query Language) (sql)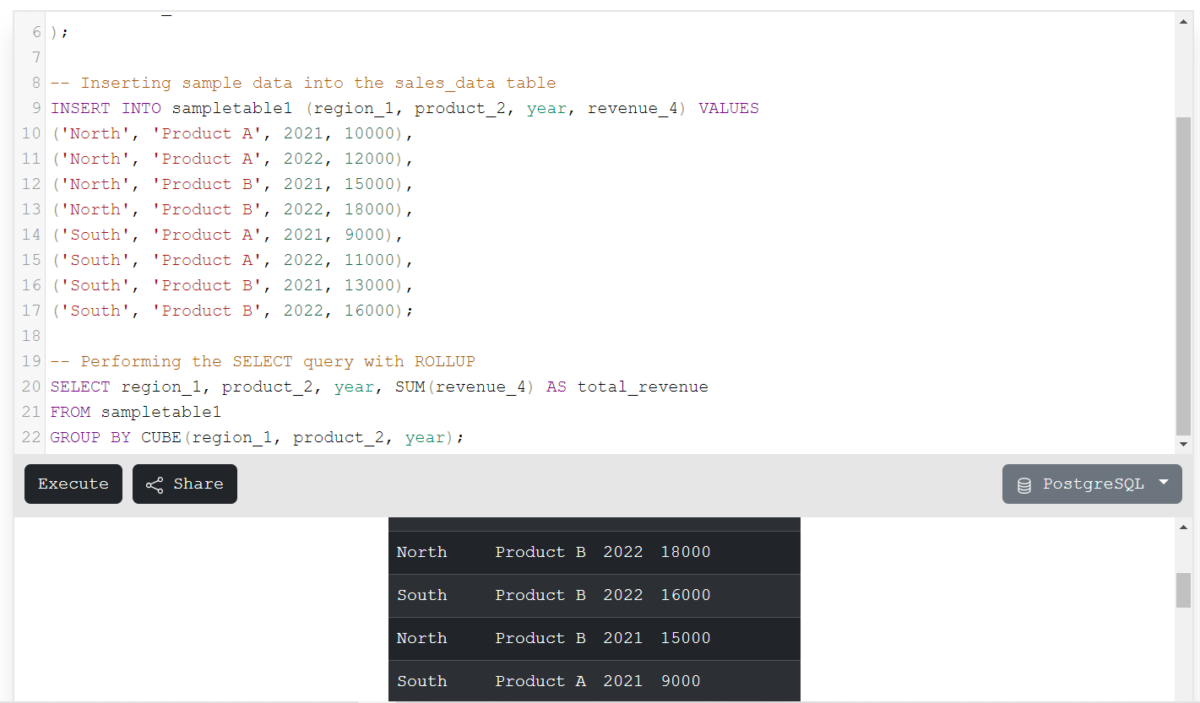
GROUPING SETS
The grouping set extension in PostgreSQL has a flexible and performing capability of backing up the hierarchical levels of the query. It provides access to a range of grouping sets that mainly consist of different sets of columns. Thus, users may compute various levels of summary statistics or subtotals with a single pass through the data. This is the most beneficial in cases where people should get into the stage where they can have reports with a more detailed view or analyze data in different dimensions at the same time.
Through the syntax that allows the definition of several grouping sets in one statement, grouping sets extension reduces the complexity of aggregation tasks and improves query performance that does not require several separate queries or complex subqueries. Let’s see an implementation.
SELECT region_1, product_2, year, SUM(revenue_4) AS total_revenue
FROM sampletable1
GROUP BY GROUPING SETS ((region_1, product_2), (region_1, year), (product_2, year), (region_1), (product_2), (year), ());
Code language: SQL (Structured Query Language) (sql)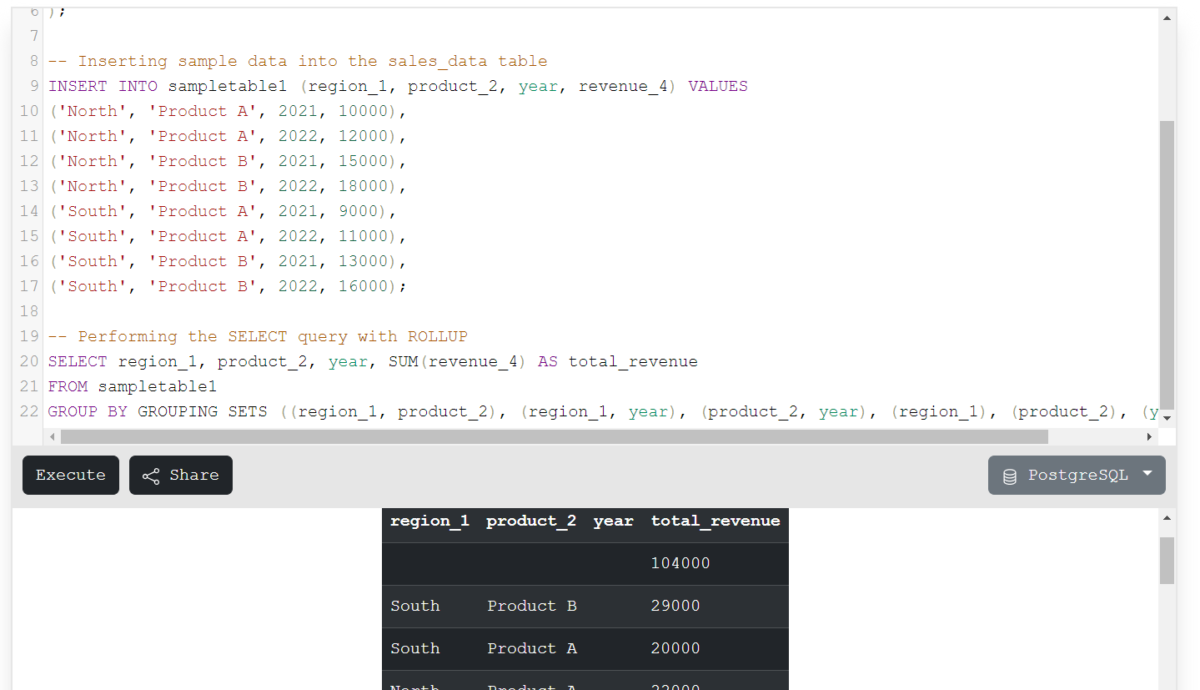
Advantages of Using GROUP BY Extensions in PostgreSQL
1. Increased Flexibility
Group By functionality (like ROLLUP, CUBE, or GROUPING SETS) provides more flexibility in specifying grouping levels than the classical GROUP BY functions. This enables the user to use the above query to produce a higher level of summarization and complex aggregations run in a snappy way.
2. Efficiency
GROUP BY extensions are usually faster performing queries compared to the use of multiple simple or complicated sub-queries. These enhancements that support the computation of various levels of aggregation and the ability to perform a single pass over the data may enhance query performance and reduce the database load.
3. Simplified Query Syntax
Group By extensions allow users to concisely and intuitively specify multiple grouping sets within a single query. This dramatically streamlines the query writing process and enhances user adoption, making it possible to write complex analytical requirements without confusing users with complicated SQL constructs.
4. Enhanced Analytical Capabilities
With Group By extensions, the PostgreSQL database turns out to be able to do advanced analytics tasks like producing sub-totals, grand totals or cross-tabulated results on multiple dimensions. It helps the users to delve deeper into their data and give more critical conclusions on the resulting analysis.
Summary
This article is based on the Group By extensions. The extensions always come with additional features in any language. In PostgreSQL, these extensions provide a wide range of applications along with Group By clause. The Rollup, Cube, and Grouping Sets extensions are implemented with the help of sampletable1. The applications covered by these extensions are also mentioned in detail. Hope you liked this article.
Reference
https://stackoverflow.com/questions/7434657/how-does-group-by-work