
The words unique and distinct are used often used interchangeably in our daily life. But when it comes to SQL, it plays totally different roles. In this tutorial, we will see the difference between the UNIQUE and DISTINCT clauses in MySQL with some examples. So, let’s get started!
Introduction
Unique and distinct are synonyms for each other. However, these two have different meanings in MySQL. The UNIQUE and DISTINCT clauses make sure that the values are not duplicated but at different places.
The UNIQUE in MySQL is one of the database constraints. Which means it plays a role to set the rules on the database tables. The UNIQUE keyword makes sure that the column does not store any duplicate value.
On the other hand, the DISTINCT clause is used with the SELECT statement to fetch the unique records from the table.
Now let’s see the detailed information and syntax of both keywords.
UNIQUE Keyword in MySQL
The UNIQUE keyword is a database constraint that is used to make sure the column does not accept the duplicate value. Note that, if a set of columns are defined as UNIQUE then the individual columns can contain duplicate values but not the combination of column’s value can’t.
Let’s see the example of the UNIQUE keyword.
CREATE TABLE uniqueDemo(
id INT PRIMARY KEY AUTO_INCREMENT,
cityCode VARCHAR(10),
cityName VARCHAR(50),
UNIQUE KEY (cityCode)
);Code language: SQL (Structured Query Language) (sql)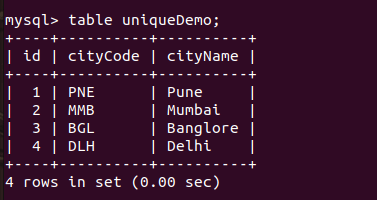
Here, we have created a table to store the city codes and city names. The city code of each city must be unique, therefore we have added the UNIQUE constraint on it. However, the city name can be different.
In the above image, you can see the table contains unique data as of now.
Now let’s try to insert the new city with the “MMB” city code which is already present in the table.
INSERT INTO uniqueDemo(cityCode,cityName)
VALUES("MMB","Mumbai");Code language: SQL (Structured Query Language) (sql)
As you can see here, we get an error that says “duplicate entry” which means the value we are trying to insert in the column already exists.
Note that, the UNIQUE constraint prevents data duplication at the time of the INSERT as well as the UPDATE statements.
You can add the unique constraint while creating a table as well as later or remove it using the alter statement. You can read the beginner’s guide on the UNIQUE constraint here.
DISTINCT Keyword in MySQL
The DISTINCT keyword is used with the SELECT statement to skip the duplicate records and return only unique rows. Note that, the UNIQUE keyword is a database constraint and can not be used in the SELECT statement. Whereas, the DISTINCT keyword is used with the SELECT statement and cannot be used as a database constraint.
Now let’s see the DISTINCT keyword in the real-time example.
We have a table called boys and have some data in it as shown in the image below.
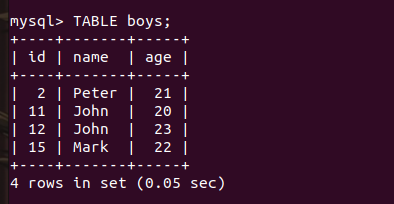
As you can see, the name “john” appears twice. But what if just want the list of names of boys without repeating any of the names? In this case, we use the DISTINCT clause.
SELECT DISTINCT(name) FROM boys;Code language: SQL (Structured Query Language) (sql)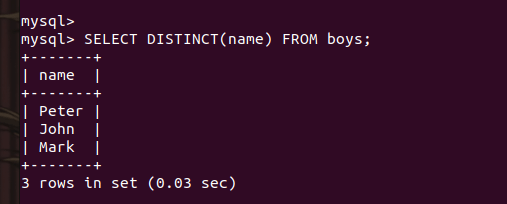
As you can see here, the name “john” now appears only once.
Wrapping Up
The DISTINCT and UNIQUE keywords are totally different from each other and are in different races. Therefore, we really can’t make a chart of the difference between these two. However, just remember that the UNIQUE keyword is a database constraint while the DISTINCT keyword is a clause which is used with the SELECT statement. Afterall both keywords make sure the data is unique and distinct 🙂