
In this tutorial, we will learn how we can handle the duplicate insertion of the record in a MySQL table. It is a very easy process and needs a single statement which is the “INSERT ON DUPLICATE KEY UPDATE”. Make sure you read the tutorial carefully and try it to understand it properly. So, let’s get started!
Also check: MySQL INSERT INTO SELECT Statement – Easy Guide
Introduction to INSERT ON DUPLICATE KEY UPDATE Statement
When a particular column in the table is set to the primary key or has a UNIQUE index, we can’t insert the same value twice in such a column. However, if we try, MySQL shows us an error.
We have to make sure that even if we try to insert the duplicate value by mistake, the old value should be updated instead of getting an error. Yet, this need not be the same in every case.
MySQL provides us with the extension to the INSERT statement – “INSERT … ON DUPLICATE KEY UPDATE”. This simply means, inserting the given values in the table. If the duplication appears, update the record with further specified values.
I hope it is more understandable and clear.
Let’s see the syntax first and we will discuss more rules and points about it ahead.
Syntax of INSERT ON DUPLICATE KEY UPDATE Statement
The following syntax shows how to use the INSERT ON DUPLICATE KEY UPDATE Statement.
INSERT INTO table (colsList)
VALUES (values)
ON DUPLICATE KEY UPDATE
col=newValue
... ;Code language: SQL (Structured Query Language) (sql)Here, if the value specified in the query is duplicate, the value will be updated in the table which is specified after the update clause.
Take the example below-
INSERT INTO t1 (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=c+1;Code language: SQL (Structured Query Language) (sql)We have three columns a,b and c, out of which the a is set to UNIQUE and has the value 1 already. Here, we are trying to insert the values 1,2,3 in columns a,b, and c respectively. Therefore, column “a” will be having a duplicate value which is not allowed.
In this case, the ON DUPLICATE KEY UPDATE statement will simply update the value of column c of the existing record instead of inserting a new record.
So, the above statement is equivalent to the following statement-
UPDATE t1 SET c=c+1 WHERE a=1;Code language: SQL (Structured Query Language) (sql)Now you might have got an idea about how this statement works.
Note that, after updating the existing record with the ON DUPLICATE KEY UPDATE statement, you will get a message that 2 rows are affected. However, only a single record gets updated. That is because-
- The affected-rows value per row is 1 if the row is inserted as a new row.
- The affected-rows value per row is 2 if an existing row is updated
- The affected-rows value per row is 0 if an existing row is set to its current values.
Also, you can update more than one value using the INSERT … ON DUPLICATE KEY UPDATE statement
Now let’s take some examples to understand it better.
Examples of INSERT ON DUPLICATE KEY UPDATE Statement
Let’s create a table first and insert some data into it. Then we will proceed to try our INSERT ON DUPLICATE KEY UPDATE Statement example.
CREATE TABLE cities(
id INT PRIMARY KEY AUTO_INCREMENT,
code VARCHAR(10) UNIQUE,
name VARCHAR(30)
);
INSERT INTO cities(code,name) VALUES
("MMB", "Mumbai"), ("DEL", "Delhi"),
("LKN", "Lakhnow"), ("PN", "Pune"),
("BNG", "Bangalore");
SELECT * FROM cities;Code language: SQL (Structured Query Language) (sql)
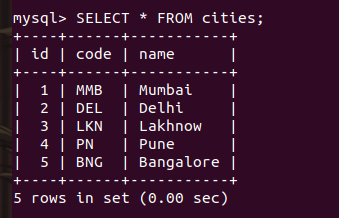
Here, we have three columns- id, code and name. The id is a primary key and also works as an auto-incrementing value. The code is a unique value for each city, therefore it will not consist of any duplicate value. The city name can be duplicated.
Then we inserted some values into it.
Now, let’s insert a new record in the table which is unique.
INSERT INTO cities(code, name) VALUES("HDBD", "Hyderabad")
ON DUPLICATE KEY UPDATE code=CONCAT(code,last_insert_id() + 1);Code language: SQL (Structured Query Language) (sql)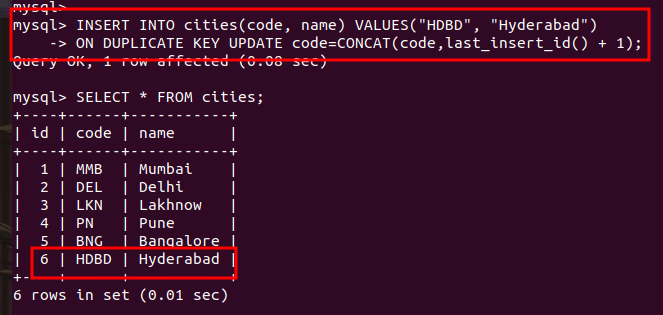
As you can see, values are inserted as a new record, therefore we got the message “1 row affected”.
Now, let’s insert a record that has the same code as the previously inserted record.
INSERT INTO cities(code, name) VALUES("HDBD", "Hyderabad")
ON DUPLICATE KEY UPDATE code=CONCAT(code,last_insert_id() + 1);Code language: JavaScript (javascript)Here, the record with code “HDBD” already exists in our table. Therefore, the above query will simply try to update the existing record with the given specified values. We are updating the code of the existing value using the last_insert_id() function which returns the id of the most recently inserted record and adds 1 to it.
Let’s see the result.
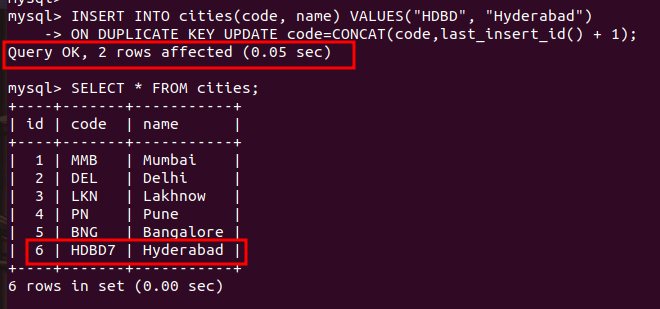
As you can see, the code of the existing record is updated and the message says “2 rows affected” that means the existing record is updated instead of adding a new record.
You can update other column values also using the comma-separated values after the UPDATE clause.
Summary
In this tutorial, we have learned how to handle the duplicate insertion of the values in our mysql table using the INSERT … ON DUPLICATE KEY UPDATE statement. You can use it in the stored procedure also to try different approaches to solve problems faced in the applications. I hope you have learned something new today. If you like this tutorial, don’t forget to share it with your friends, because sharing is caring!!
References
MySQL official documentation on the INSERT ON DUPLICATE KEY UPDATE statement.