Duplicate values in a table are a main hurdle in data management. The aim of database management also includes the responsibility of maintaining data quality and consistency. Duplicate data entries may be found in the table which decreases the overall quality of the database. Finding those values from the table is a very important task. In this process, we need to manage the rows that share duplicate data in the respective columns.
In this article, we are exploring different techniques to find duplicate values and also some ways to maintain and manage the uniqueness of the database.
Why Find Duplicate Values in a Table?
Managing the duplicate values in the table helps to maintain data integrity. If the table/ database contains the unique values then, the overall quality of the database increases.
There are many reasons why we need to find duplicate values and maintain data integrity. The basic reason is to maintain the accuracy of the data. In many scenarios, the duplicate data may lead to confusion. For example, the problem of behavioural analysis of the customer data. The duplicate values will not analyze the correct behaviour of the customer towards a specific product. In this case, finding duplicate values from the table becomes a very important task. In some cases, if we want to draw patterns using available data then, the duplicate values are a main problem. All the patterns will be misinterpreted due to these duplicate values.
Duplicate values also hold a large amount of storage space for the same data. In large datasets, it is a very important task to manage the storage space for the data. To optimize the dataset we need to track these duplicate values. The healthcare industry is totally based on the data and this data is available on a large scale. Duplication will lead to many complicated problems while analyzing the data. The possibility of error in this case is very high. This is risky and complicates the overall process.
Finding Duplicate Values in MySQL Table
We can use different SQL queries to identify the duplicate values from the table. Let’s understand the process of finding duplicates with the help of some examples.
Creating a Table for Demonstration
The table we will create consists of three columns: id, first_name, and email. The first column contains an integer type of data. The second column contains the names of the users. The third column consists of the email.
CREATE TABLE employees
(`id` int, `first_name` varchar(5), `email` varchar(17));
INSERT INTO employees
(`id`, `first_name`, `email`)
VALUES
(1, 'John', '[email protected]'),
(2, 'Jane', '[email protected]'),
(3, 'Mike', '[email protected]'),
(4, 'Emily', '[email protected]'),
(5, 'Mark', '[email protected]'),
(6, 'Sarah', '[email protected]');Code language: SQL (Structured Query Language) (sql)This will create a table for the implementation.
Finding Duplicate Values Using ‘GROUP BY’ and ‘HAVING’ in a Single Column
The duplicate value can be tracked using different SQL queries for example the ‘GROUP BY‘ and ‘HAVING‘. Both are used to gather all the value that is identical and provides a summary-like structure with the specified value. This will also help to filter specified values from the table. This technique can be applied to a single column and to multiple columns. Let’s see the implementation for a better understanding.
Query:
SELECT email, COUNT(*) AS count
FROM employees
GROUP BY email
HAVING COUNT(*) > 1;Code language: SQL (Structured Query Language) (sql)This code will be able to find the duplicate email from the employee table. The ‘COUNT(*)’ function helps to count the frequency of duplicate values. Let’s see the result.
Output:
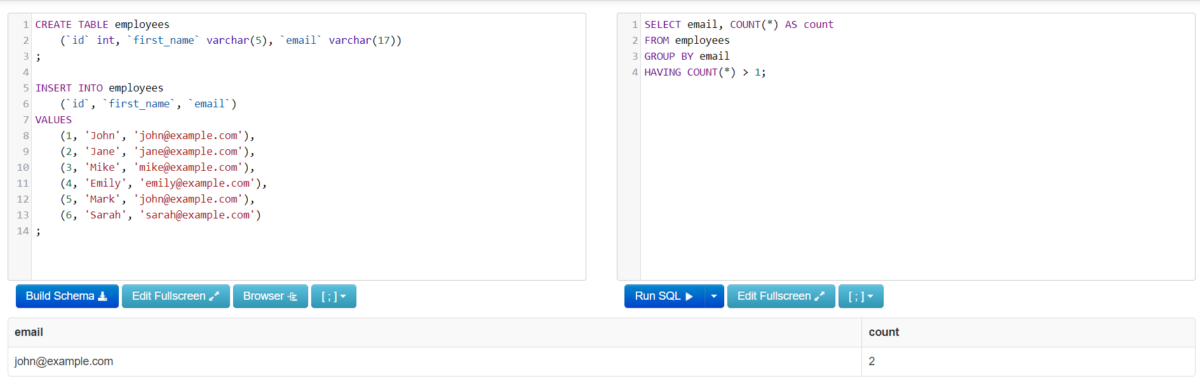
You can use the same code to track the duplicate value in any table.
Finding Duplicate Values Using ‘Self Join’
The ‘Self Join‘ query will print the details and duplicate values. Self-joins will provide the ability to compare all the data of a particular column with one another. This technique is very useful for comparing all the values of the tables.
There is the concept of aliases in this technique. This will help to compare all the values.
Query:
SELECT e1.id, e1.first_name, e1.email
FROM employees e1
JOIN employees e2 ON e1.email = e2.email AND e1.id <> e2.id;Code language: SQL (Structured Query Language) (sql)In this code, the e1 and e2 are the aliases or the unique numbers assigned to every row. The ‘JOIN’ will compare each handle with the other row. This method will track the duplicate value easily.
Output:
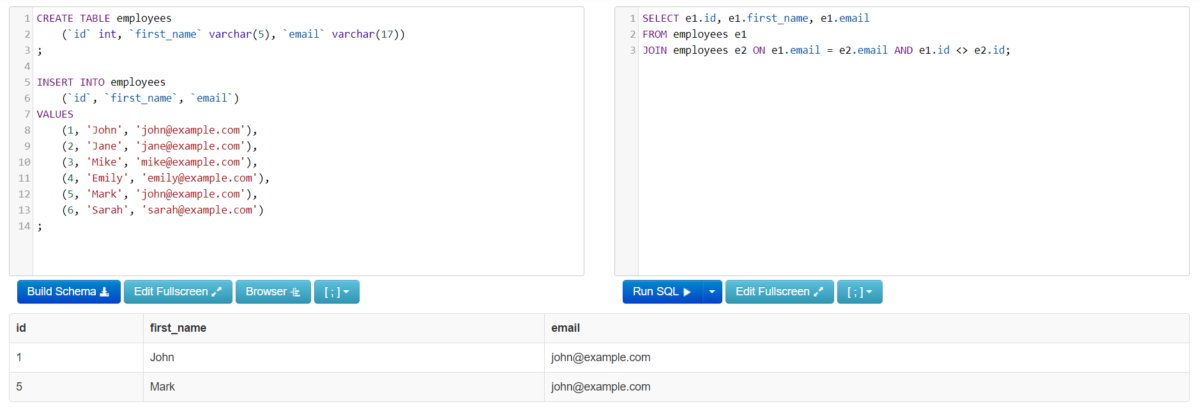
In the result, we can clearly able to see the duplicate email IDs of two different aliases.
Finding Duplicate Values in Multiple Columns
We can also find duplicate values in multiple columns using the same ‘GROUP BY’, and ‘HAVING’. Let’s understand with the help of an example.
CREATE TABLE Example
(`id` int, `first_name` varchar(4), `last_name` varchar(7), `email` varchar(24));
INSERT INTO Example
(`id`, `first_name`, `last_name`, `email`)
VALUES
(1, 'John', 'Smith', '[email protected]'),
(2, 'Jane', 'Doe', '[email protected]'),
(3, 'John', 'Smith', '[email protected]'),
(4, 'Mary', 'Johnson', '[email protected]'),
(5, 'Jane', 'Doe', '[email protected]');Code language: SQL (Structured Query Language) (sql)Here, a table is created with the four columns, Let’s try to write code to find duplicate values.
Query:
SELECT first_name, last_name, COUNT(*) as duplicate_count
FROM Example1
GROUP BY first_name, last_name
HAVING COUNT(*) > 1;Code language: SQL (Structured Query Language) (sql)The duplicate values from the table should reflect in the output with the first_name and last_name pair.
Output:
2 duplicate values are found for each pair of first_name and last_name columns.
Summary
The quality of the dataset depends upon the uniqueness of the values. If duplicate values are present in a large quantity, it will affect the overall result of the model. The duplicate values can be tracked using different SQL queries. This query can be applied to single columns and multiple columns as well. In this article, techniques are explained in detail. Hope you enjoyed reading the article.
Reference
https://stackoverflow.com/questions/854128/find-duplicate-records-in-mysql