
You may have faced several situations where the same rows in a MySQL table are inserted twice or more. It is very important to ensure that no duplicate data resides in the table. So, in this tutorial, we are going to learn how to delete duplicate data from the table. Not only one but we will see three simple and easy methods to delete duplicate rows from the table. Here we go!
Before We Start
As stated earlier, we will see three methods to delete duplicate rows in the table. All three methods are very easy and simple to execute.
The first method is straightforward and it uses the DELETE JOIN statement which is provided by MySQL to delete duplicate rows.
The second method is not so efficient but it still works. In this method, we will create a new table and insert only unique rows from the first table into it. After that, we will delete the first table and rename the second table as the first table.
The third method uses the row_number() function and nested SQL queries to find the duplicate rows and delete them all. This is a slightly difficult method but still, you can use it.
Examples to Delete Duplicate Rows From MySQL Table
Before demonstrating the examples, let’s create a table and insert data into it. We will also insert some duplicate rows into the table.
CREATE TABLE contacts(
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
city VARCHAR(100)
);Code language: SQL (Structured Query Language) (sql)INSERT INTO contacts(name,email,city)
VALUES("Jenos Adams","[email protected]","LA"),
("Peter Parker", "[email protected]", "LA"),
("James Anderson", "[email protected]", "Boston"),
("Peter Parker", "[email protected]", "LA"),
("May Bailey","[email protected]","NY"),
("Rock Hardy","[email protected]", "LV"),
("James Anderson", "[email protected]", "Boston");Code language: SQL (Structured Query Language) (sql)SELECT * FROM contacts;Code language: SQL (Structured Query Language) (sql)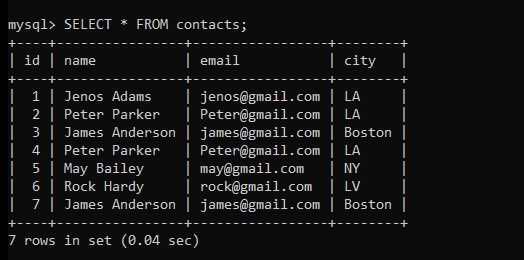
We are all set now. Let’s see the first example.
Method 1. Delete Duplicate Rows Using DELETE JOIN
This is the easiest method of all methods. It uses the DELETE JOIN statement that helps to delete all duplicate rows from the table.
The following query deletes all the duplicate rows.
DELETE c1 FROM contacts c1
INNER JOIN contacts c2
WHERE
c1.id < c2.id AND
c1.email = c2.email;Code language: SQL (Structured Query Language) (sql)Here, c1 and c2 are the aliases given to the same table. We are deleting the common rows where two emails are the same and the row which has the highest id remains as it is.
Let’s display the table data to check if the above query was executed successfully.
SELECT * FROM contacts;Code language: SQL (Structured Query Language) (sql)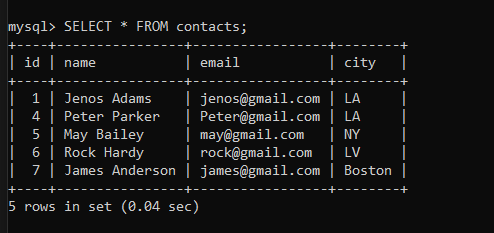
As you can see, all duplicate rows are deleted.
Method 2. Delete Duplicate Rows Using Second Table
In this method, we will find only unique rows from the first table and insert them into the second table, so that the new table will contain only unique data. Then we will delete the first table and rename the second table as the first table.
We will follow the below steps-
- We will create a table of the same structure.
- Then we will insert unique rows from the first table into the new table.
- Finally, we will delete the first table and rename the second table to the original.
Let’s start by creating a table.
CREATE TABLE contactsCopy(
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
city VARCHAR(100)
);Code language: SQL (Structured Query Language) (sql)Now, insert unique data from the first table.
INSERT INTO contactsCopy(name,email,city)
SELECT name,email,city FROM contacts
GROUP BY email; -- duplicate rows based on email columnCode language: SQL (Structured Query Language) (sql)Here, we have copied the values of the name, email and city columns into the new table.
Let’s display the new table data to check if only unique data is copied.
SELECT * FROM contactsCopy;Code language: SQL (Structured Query Language) (sql)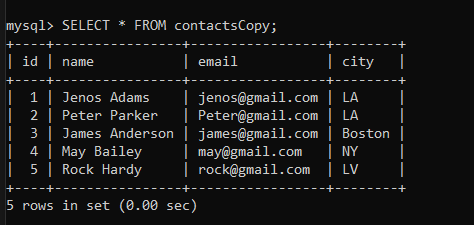
As you can see, only unique data is copied into the table “contactsCopy”.
Now delete the previous table and rename the new table as the old table.
DROP TABLE contacts; #deleting first table
ALTER TABLE contactsCopy RENAME TO contacts; # renaming the contactsCopy table to contacts
Code language: SQL (Structured Query Language) (sql)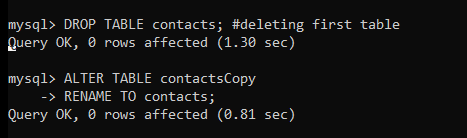
As you can see, the old table is deleted and the new table is renamed to the old table name.
Method 3. Delete Duplicate Rows Using the ROW_NUMBER() Function
The ROW_NUMBER() function assigns a sequential integer number to each row. If duplicate data is found then the row number will be greater than one.
The following query will assign the row numbers.
SELECT name,email, row_number() OVER (PARTITION BY email) AS row_num FROM contacts;Code language: SQL (Structured Query Language) (sql)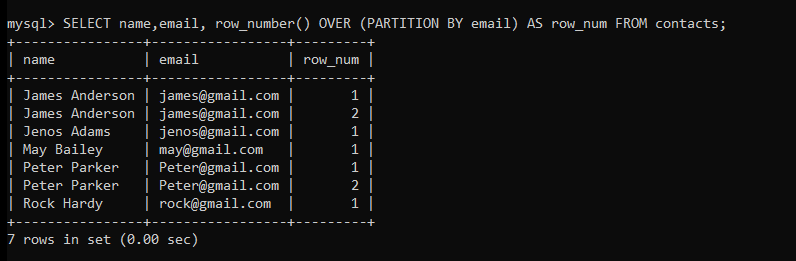
As you can see in the above image, the duplicate rows get the number 2.
Now, we will use the above query and delete the duplicate rows which have a row number greater than 1.
DELETE FROM contacts WHERE
id IN(SELECT id FROM(
SELECT id, row_number() OVER(PARTITION BY email)
AS row_num FROM contacts) c
WHERE row_num>1
)Code language: SQL (Structured Query Language) (sql)Here, we have used nested queries to delete the duplicate rows.
Let’s display the table data to check if the duplicate data is deleted.
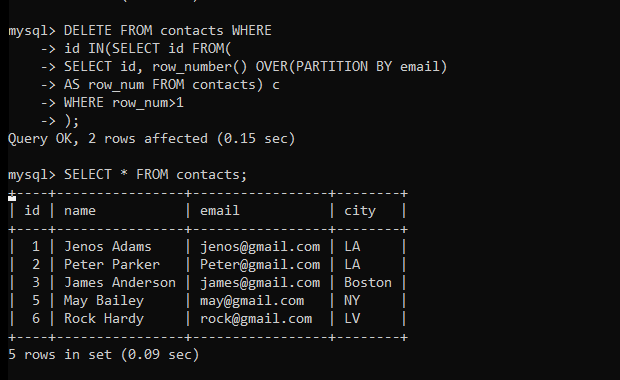
As you can see, we have now only unique rows in our table which mean all duplicate rows are deleted.
Summary
In this article, we have learned-
- Introduction to the topic.
- Ways to delete duplicate rows from the table.
- Method 1- Delete duplicate rows using the DELETE JOIN statement.
- Method 2- Delete duplicate rows using the second table.
- Method 3- Delete duplicate rows using the ROW_NUMBER function.